Using UNICODE in Maintained AIMMS Applications
AIMMS 4 uses UTF8 as default character set, where all UNICODE characters are allowed. Some older AIMMS applications were developed based on ASCII, and can be upgraded to use UTF8, thus empowering users with texts using the UNICODE character set.
This brief article:
outlines encoding terminology
charts character sets by AIMMS version
discusses changing character sets
defines how to upgrade AIMMS projects to allow
UNICODE
Introduction to Encoding
Text files are stored as a sequence of numbers and the characters corresponding these numbers are viewed as “text”.
The mapping of characters to numbers is an encoding, and there are a few different standard character sets.
Nowadays, the dominant character set is UNICODE, and the dominant encoding is UTF8.
When a text file using one encoding is ported to a program using another encoding, the mapping doesn’t match and the characters are not translated as intended.
History on the Use of Character Sets in AIMMS
AIMMS 2 used the
ASCIIcharacter set, the dominant character set at the time. AIMMS 2 used the common implementation of using one byte per character.AIMMS 3.0 and AIMMS 3.1 also used
ASCIIas the only character set and encoding supported. The AIMMS projects created with these AIMMS releases were agnostic to the code page at hand.AIMMS 3.2 introduced the option to use two characters for encoding and supported a 16-bit encoding of
UNICODE. Two different installers were available, one forASCIIversions of AIMMS, and one for theUNICODEversion of AIMMS. This remained until AIMMS 3.13. TheASCIIversions of these AIMMS releases were all agnostic to the code page in use.AIMMS 3.14 introduced the concept of encoding, supporting more than 50 different encodings; different code pages were counted as different encodings. New projects created with AIMMS 3.14 used the
UTF8encoding by default. This is also available in modern versions of AIMMS 4.
Consequences of Choosing a Different Encoding
See also Set Encoding Format
Options were introduced to handle different encodings for different IO:
Aim character encoding. The character encoding used to interpret
.aimfiles. For AIMMS 3 systems, text copies of the model were stored using the AIM 3 format. The current.amsformat always usesUTF8. Therefore, this option is no longer relevant.ASCIICase character encoding. This option determines the encoding used to decode strings stored in a case file constructed by anASCIIAIMMS 3.13 or older release. Cases created using AIMMS 3.14 or later useUTF8character strings anyway. So, if you do not have cases created using AIMMS 3.13 or older, you can safely set this option to its default.Default input character encoding. This option sets the default encoding when a text file is read in. Reading data from text files using the Read from File statement. File nowadays are often
UTF8; so this is only relevant if you use code pages. The value of this option is ignored for files whereby the attributeencodingis specified.Default output character encoding. This option sets the default encoding when a text file is written, for instance using
PUTstatements or Write to File statements. The value of this option is ignored for files whereby the attributeencodingis specified.External string character encoding. This option determines the encoding used to communicate the value of a string parameter that is the argument of an external function with the external library. Only relevant when external libraries are used that rely on this option.
Datatable character encoding. This option is no longer in use and can safely be set to its default.
NB: Possible values for these option are the elements in the predeclared set AllCharacterEncodings.
Converting ASCII Based Apps to Using UTF8
First check which options are at non-default:
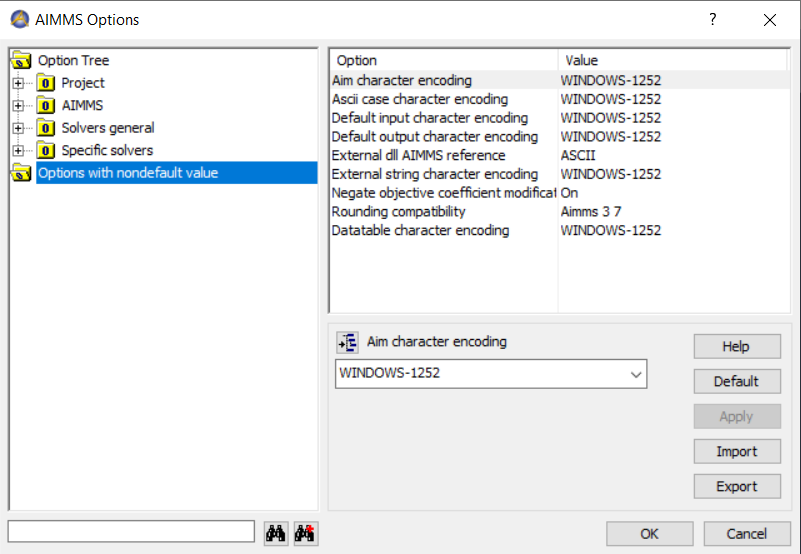
For each encoding option not at its default, please check whether the consequences mentioned above are applicable to your project.
If not, you can safely set it to the default of UTF8; thus enabling all UNICODE characters.