Waiting for sub jobs to complete
Introduction
For large jobs, it may make sense to split it into multiple jobs. It may not be convenient, or appropriate, to let the client session organize the communication between the various jobs.
This article presents and discusses an example, whereby one control job manages several sub jobs. In addition, results are presented in the client session when all jobs are finished.
This article focuses on illustrating:
Submitting sub jobs, whereby
delegationOverrideis used,waiting on the completion of sub jobs using the procedure
pro::messaging::WaitForMessages, andcustomizing completion callback procedures.
The running example
A transport problem with two origins and two destinations. The demand and supply are both fixed and matching. The unit transport cost between the origins and destinations are unknowns and vary considerably.
An overview is requested by generating various scenarios, and comparing the runs.
The example to download:
Focus
This article focuses on job creation and communication between jobs. This article does not focus on analysis of results.
Structure of article
Overview of information flow
Waiting on sub jobs
Best practice considerations
Overview of information flow
The information flow between client session, control job, and sub jobs is depicted below:
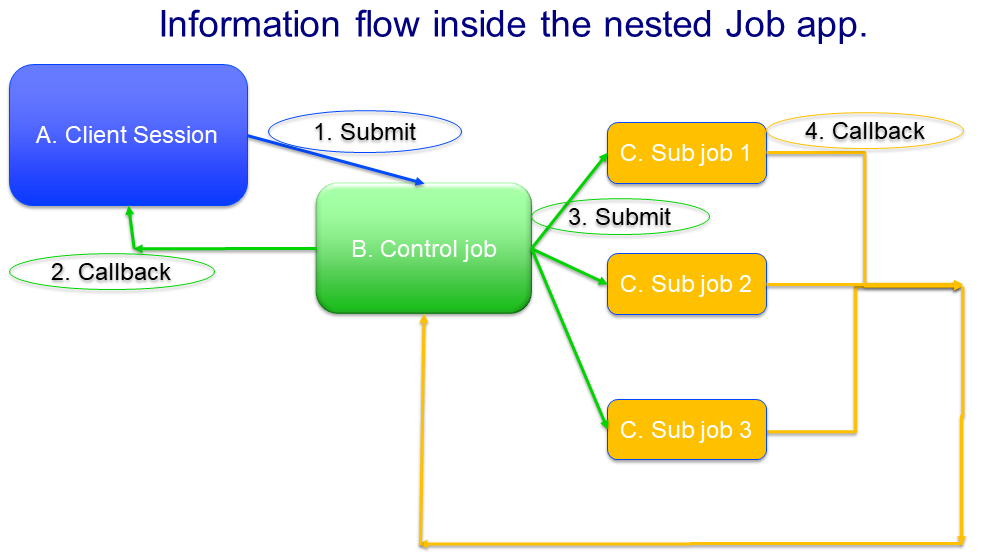
Blue, the client session:
Collect the inputs for the Solver Session, and start it as
Control job.How to: 👇 (click to open text)
Construct input case via sections and pro::ManagedSessionInputCaseIdentifierSet.
As an example consider the following excerpt from
MainExecution:1pro::ManagedSessionInputCaseIdentifierSet := 2 scj::solver_control_job_input_output_declarations + 3 scj::solver_control_job_input_declarations + 4 wsj::static_inputs_sub_job ;
This will put the identifiers declared in the sections
scj::solver_control_job_input_output_declarations,scj::solver_control_job_input_declarations, andwsj::static_inputs_sub_jobin the input case.Submit job by
pro::DelegateToServer, as illustrated in the following excerpt fromscj::pr_globSol1if pro::DelegateToServer( 2 requestDescription : "solver control job", 3 waitForCompletion : 0, 4 completionCallback : 'scj::pr_globSolCallback' 5 ) then 6 return 1 ; 7endif ;
Line 2: requestDescription: When multiple jobs are involved, it is worth paying attention to the job description. For starters, this makes identifying the job in the jobs tab of the AIMMS Portal easy.
Line 3: waitForCompletion: Not waiting for completion. This will allow the user to continue interacting with the application whilst the control session is working to obtain the desired results. See also these how tos
Line 4: completionCallback: Specify the procedure to process the output case upon completion. Note that the library and module prefixes are needed here, when this procedure happens to be declared in a library/module to unambiguously identify the procedure in the set AllIdentifiers.
Not specified: delegationOverride: The client session uses the default of this argument, and therefore it is not specified here.
When the
B. Control jobfinishes, the client session receives its results.How to: 👇 (click to open text)
The results of the solver session
B. Control Job.are to be put in the output case, and this is done in the session of that job. Thus thepro::ManagedSessionOutputCaseIdentifierSetneeds to be assigned in theB. Control Job.. As an example, the procedurepr_workGlobSolcontains the following code:1pro::ManagedSessionOutputCaseIdentifierSet := 2 solver_control_job_input_output_declarations + 3 solver_control_job_output_declarations ;
Process the data in the output case by the
A. Client Session.The completion callback procedure
scj::pr_globSolCallbackexecutes inside the client session, and accesses data relevant to that session.The procedure
scj::pr_globSolCallback(sp_requestDescription)is invoked upon completion of the solver sessionControl Job. The argumentsp_requestDescriptioncan be used bypro::session::LoadResultsCallBackto actually load the case.1Procedure pr_globSolCallback { 2 Arguments: (sp_requestDescription); 3 Body: { 4 ! Load results from output case of subjob. 5 pro::session::LoadResultsCallBack(sp_requestDescription); 6 7 ! Opportunity to add some application specific code for receiving final solution here. 8 } 9 StringParameter sp_requestDescription { 10 Property: Input; 11 } 12}
Perhaps more friendly is to notify the user first and permit that person loading the data at a convenient moment, see: Load solver session Results Manually.
Green, the Control job.
Collect the inputs for a sub job and start that sub job.
How to: 👇 (click to open text)
Construct input for a sub job.
Similar as in step 1, the input case is specified by
pro::ManagedSessionInputCaseIdentifierSetin the following excerpt fromscj::pr_submitAllSubjobs1! Each sub job get the data from the following sections: 2pro::ManagedSessionInputCaseIdentifierSet := 3 wsj::inputs_outputs_sub_job + 4 wsj::inputs_sub_job + 5 wsj::static_inputs_sub_job ;
By specifying
pro::ManagedSessionInputCaseIdentifierSetin theB. Control job; the app developer does not need to worry about accidentally influencing the input specification of theB. Control Jobitself as this is done in theA. client session. More specifically:The
A. Client Sessionand`B. Control Jobare different processes, thus the identifierpro::ManagedSessionInputCaseIdentifierSetin these two processes does not share memory.As this is an identifier in the library
AimmsProLibrary`, and this library has the propertyNoSaveset, the contents of this identifier in these two libraries is not accidentally overwritten by the transfer of data via a case.
Start the sub job. This is done in the procedure
scj::pr_delegateSubSol.1if pro::DelegateToServer( 2 requestDescription : formatString("Sub job %s", wsj::sp_thisJob), 3 waitForCompletion : 0, 4 completionCallback : 'wsj::pr_subSolCallback', 5 delegationOverride : 2 6 ) then 7 return 1 ; 8endif ;
Line 2: requestDescription: Again, when multiple jobs are involved, it is worth paying attention to the job description.
Line 3: waitForCompletion: Not waiting for completion. This will allow the control job to continue processing.
Line 4: completionCallback: Specify the procedure to process the output case upon completion.
Line 5: delegationOverride: The
B. Control Jobhas delegation level 1, so delegation level 2 is needed for aC. Sub job, see Distributing Work
When a
C. Sub jobfinishes, the control job receives the results.How to: 👇 (click to open text)
Specify the output case to be constructed by a
C. Sub job. As you probably expect by now, this is done in the procedurewsj::pr_subsolas follows:1pro::ManagedSessionOutputCaseIdentifierSet := 2 inputs_outputs_sub_job + 3 outputs_sub_job ;
Process the output case by the
B. Control job.1Procedure pr_subSolCallback { 2 Arguments: (sp_requestDescription); 3 Body: { 4 5 ! Load results from output case of subjob. 6 pro::session::LoadResultsCallBack(sp_requestDescription); 7 8 ! Identify the subjob whose solutions is just read in. 9 ep_subJob := StringToElement( scj::s_subJobNames, sp_thisJob ); 10 11 ! Store the solution of the sub job in the declarations of the global job. 12 scj::p_solutionsPerJob(ep_subJob, i_from, i_to) := v_transport(i_from, i_to); 13 scj::p_objectivesPerJob(ep_subJob) := v_totCost ; 14 15 ! Increment the number of subjobs that shared their solution with the global job. 16 scj::p_noReceivedSolutions += 1 ; 17 } 18 StringParameter sp_requestDescription { 19 Property: Input; 20 } 21 ElementParameter ep_subJob { 22 Range: scj::s_subJobNames; 23 } 24}
Remarks:
Line 6: First load the case
Line 9: The name of the job is passed back. Avoid passing the set of job names: in larger applications this set may be very dynamic. Thus it is important that reading a case from a sub job, does not influence the set of job names already created in
B. Control job.Lines 12-13: Multiple jobs will contain information on the same identifiers; thus collecting information per job needs to be explicit for all identifiers passed back from a
C. Sub jobto theB. Control job.Line 16: The number of received solutions is carefully administered; as this indicates to the
B. Control jobwhen all information is gathered.
Yellow, a sub job.
Waiting on sub jobs
A completion callback procedure is passed as a message from the called job, here C. Sub job, back to the calling job, here B. Control job.
These messages do not have a priority.
If no precautions are taken, these messages will be handled after the delegated procedure scj::pr_globSol of B. Control job finishes.
The intent of the app, however, is to let B. Control job collect results, perhaps do some processing of its own, then pass the results back to the client session.
Luckily, the AIMMS Cloud procedure pro::messaging::WaitForMessages permits to check and handle any message received.
An example is provided in the following:
1p_timeout := 60 /* seconds */ ; ! Should be configurable.
2sp_startTime := CurrentToString( "%c%y-%m-%d %H:%M:%S:%t%TZ('UTC')" );
3while p_noReceivedSolutions < p_noSubmittedJobs do
4 ! p_noReceivedSolutions is incremented when a sub job callback is processed by pro::messaging::WaitForMessages
5 pro::messaging::WaitForMessages("",0,10/* milli seconds */);
6 sp_now := CurrentToString("%c%y-%m-%d %H:%M:%S:%t%TZ('UTC')");
7 p_elapsedTime := StringToMoment(
8 Format : "%c%y-%m-%d %H:%M:%S:%t%TZ('UTC')",
9 Unit : [s],
10 ReferenceDate : sp_startTime,
11 Timeslot : sp_now);
12 pr_trace(formatString("p_noReceivedSolutions = %i, p_noSubmittedJobs = %i, elapsed = %n",
13 p_noReceivedSolutions, p_noSubmittedJobs, p_elapsedTime ) );
14 if p_elapsedTime > p_timeout then ! waiting loop timed out - some subjob likely not able to present solution.
15 break ;
16 endif ;
17endwhile ;
Remarks:
Line 3: check if sufficient solution have been received.
Line 5: The call to
pro::messaging::WaitForMessages.The first two arguments are filters on the messages received and handled; respectively on the queue name, and on the type of message. Passing “” and 0 as first two arguments is interpreted as: do not filter on queue and do not filter on type.
The third argument is a timeout. Here 10 milliseconds, corresponding to one tick, is used.
Line 14: Did we exceed the timeout.
Note
The concern mentioned in this section is not a concern for a WinUI or WebUI client session. For such a session, there will be idle time between procedures executed and then the completion callback message is handled.
Best practice considerations
Avoid over structuring
Avoid over structuring into separate jobs. This is because submitting a job has the following steps:
construct input case by calling process
start new process
Compile app, and perform app initialization
transfer input case, Both WinUI caller, and on cloud this may be on different machines!
read input case
actually execute the delegated procedure
write output case
transfer output case to calling process
read output case by calling process
When step 6 is small, the relative overhead of the other steps may be high!
Resource considerations
When multiple processes are actively executing at the same time on a single machine, it is important to avoid thread starvation.
Please note that Both CPLEX and the AIMMS Execution engine may deploy multiple threads for efficient execution. If there is also parallelization by doing multiple AIMMS Cloud jobs simultaneously, thread starvation may occur. When there is thread starvation, the overall performance is likely to be disappointing. Both CPLEX and AIMMS provide option settings that limit the number of threads used:
CPLEX: global_thread_limit
AIMMS: Number_of_execution_threads
Note
For the AIMMS Cloud this consideration is irrelevant. In the AIMMS Cloud each job gets its own docker image. Therefore, such a job can behave as if it is the only active process 😉.